Overview
CoinBook is a desktop accounting application written in Java. It is targeted at cryptocurrency traders and enthusiasts, and allows them to keep track of the coins they hold, obtain price data and analytics, and read the latest news relevant to them in the same place. Primary interaction is through a CLI, and a GUI built with JavaFX.
Summary of contributions
-
Major enhancement: Added advanced search criteria and boolean logical operators
-
What it does: Allows the user to search through the CoinBook based on Code, price, etc as well as boolean combinations of these.
-
Justification: This lets users search through a large set of coins quickly as well as allow users the power of very specific queries. This allows for ease of use and handling of a large Coin base.
-
Highlights: This enhancement involved revamping the entire input sanitation to allow for a higher level of parsing. The resulting system was then used by enhancements written by other team members. Many alternative design considerations were made and tradeoffs were sacrificed.
-
Credits: Concepts of tokenization, parsing, syntax specification and boolean predicate generation were covered extensively in Compilers: Principles, Techniques, and Tools by Alfred V. Aho, Monica S. Lam, Ravi Sethi, and Jeffrey D. Ullman. The conceptualization of the parser would not have been possible without the valuable lessons obtained from that book.
-
-
Proposed extensions :
-
Boolean logical queries may be difficult for users to consistently express. One possible enhancement could be to include syntax highlighting on the text as it is typed in to notify the user when the string is valid without requiring the user to use the
Enterkey. -
It could be very useful to automatically translate such boolean queries into English as the user types the queries, to give them a sense of what their expression means. For example: when the user keys in
(p/>50 AND t/fav) OR c/BTCit could be possible for some text to appear with the following sentence: "Based on this query, you wish to find all coins that are priced above 50 dollars and you have tagged as favourite. Also, you wish to find the coin named BTC". -
The Tokenizer, along with its TokenTypes and the SyntaxParser was designed to be extensible in the case there needs to be a drastic change in syntax. An approach to the Unix-style command line interface is another possible direction.
-
-
Minor enhancement: Added a news panel which loads subreddits for coins through the view command when invoked. Also provided the ability for CoinBook to warn the user when the coin added does not exist.
-
Code contributed: [Functional code] [Test code]
-
Other contributions:
-
Project management:
-
Managed releases
v1.5rc(1 release) on GitHub
-
-
Enhancements to existing features:
-
Documentation:
-
Community:
-
Reported bugs for other teams in the class(examples: 1)
-
-
Tools:
-
Used PlantUML for generating diagrams for the Developer Guide == Contributions to the User Guide
-
-
Given below is the main section I contributed to the User Guide. They showcase my ability to write documentation targeting end-users. |
Search through accounts find | f [Since v1.4]
find CONDITION
|
Must follow the format listed below |
Updates the listing to show only coin accounts whose details satisfy the given condition.
find c/BT
Finds accounts with BT in their code
find t/fav
Finds accounts with the fav tag
find (p/>500 AND t/fav) OR h/<20
Finds accounts either with current price more than $500 and tagged fav, or with less than 20 coins left
Contributions to the Developer Guide
Given below is the main section I contributed to the Developer Guide. They showcase my ability to write technical documentation and the technical depth of my contributions to the project. |
Condition Parser Component
Current implementation
The general parser for the SQL-like arguments for the find command can be broken down into a few sub-components, namely ArgumentTokenizer, SyntaxParser, SemanticParser, and a ConditionGenerator, while using classes such as Condition,
Token, TokenType, TokenStack to model the data that is to be operated on throughout the process. Their tasks are
delegated as follows:
-
ArgumentTokenizer: Lexically analyzes the input string, then creates a list of tokens -
SyntaxParser: Parses the input by matching the tokens versus a list of rules to ensure they fit the desired structure -
SemanticParser: Parses the input by matching the tokens versus a list of rules to ensure their meaning is semantically valid -
ConditionGenerator: Uses the list of tokens to create the equivalent lambda function to evaluateCoinobjects against. -
Condition: Serves as a wrapper/container for the boolean lambdas used to evaluate coins for filtering purposes. -
Token: Serves as a container for the sectioned input strings.
|
The distinction between the Syntax Parser and the Semantic Parser is that the former is oblivious as to what the
input actually means, and only cares whether the structure is correct, whereas the latter verifies the meaning behind the
input. For example, n/BTC AND OR p/>500 is invalid syntatically, whereas n/BTC or p/>BTC is valid syntatically
but not semantically, since it would not make sense to search for Coin objects whose price attribute was more than
"BTC" (prices cannot be compared to names).
|
The following sequence diagram (Fig. 11) will show how input arguments accompanying the find command are parsed:
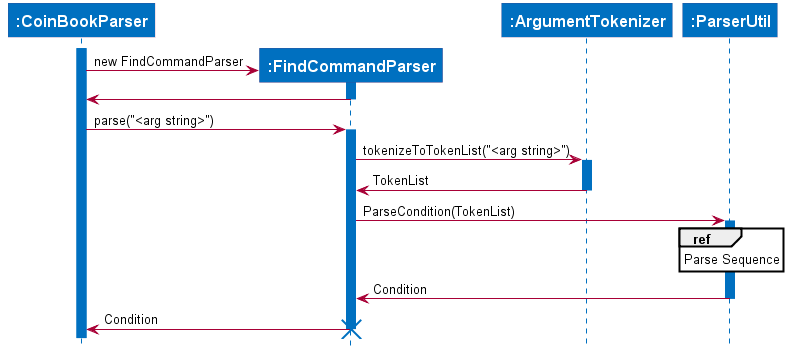
The SyntaxParser, SemanticParser and ConditionGenerator classes reside in a separate module that will be called by the
ParserUtil class during the ParseCondition method.
The following activity diagram (Fig. 12) expands on the Parse Sequence block in the previous diagram.
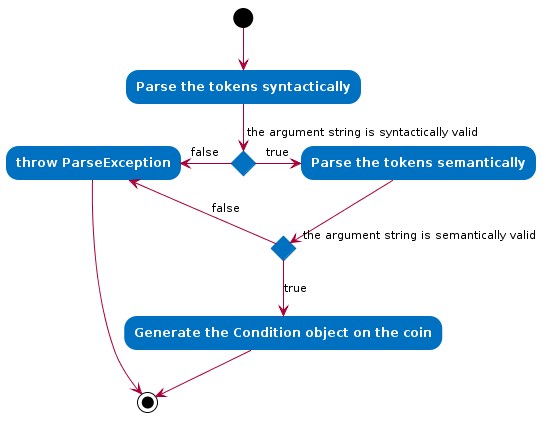
The Condition object that is generated at the end is actually just a Predicate object that evaluates properties of
the Coin objects and returns a true/false value.
Error handling
On syntactically and semantically invalid inputs, ConditionParser will retrieve the expected and actual type of
Token that were not a match during the parsing phase from TokenStack and raise a ParseException before returning.
In the event that strings intended to represent tags or numbers are not valid, an IllegalValueException is raised instead,
as per convention from ParserUtil.
Advanced Details
Argument Tokenizing
We will illustrate the flow of tokenizing an example input:
> n/BTC OR ( t/fav AND p/>100 )The Lexer would tokenize this into:
> [n/,OPTION][BTC,STRING][OR ,BINARYOP][(,LEFTPAREN][t/,OPTION][fav,STRING][AND,BINRARYOP][p/,OPTION][>,COMPARATOR][100,NUMBER][),RIGHTPAREN]Notice how the whitespace has now been discarded, since it is not used for the purposes of parsing. Also each section of the input (i.e. token) has now been grouped with a type.
Below is a sequence diagram (Fig. 13) describing the behaviour of ArgumentTokenizer on the input:
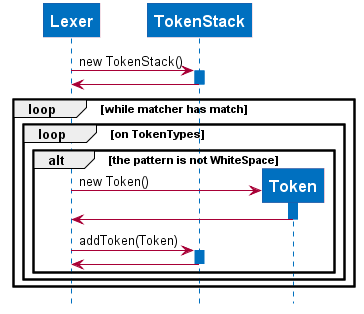
ArgumentTokenizer ClassSyntax Parser
Next, the syntax parser has to ensure that the sequence of tokens is actually structurally valid. This is done by matching the tokens off based on the following rules, expressed in Backus-Naur form:
-
EXPRESSION:=TERM|TERMBINARYOPEXPRESSION -
TERM:=LEFTPARENEXPRESSIONRIGHTPAREN|UNARYOPTERM|CONDITION -
CONDITION:=OPTIONCOMPARATORNUM|OPTIONSTRING
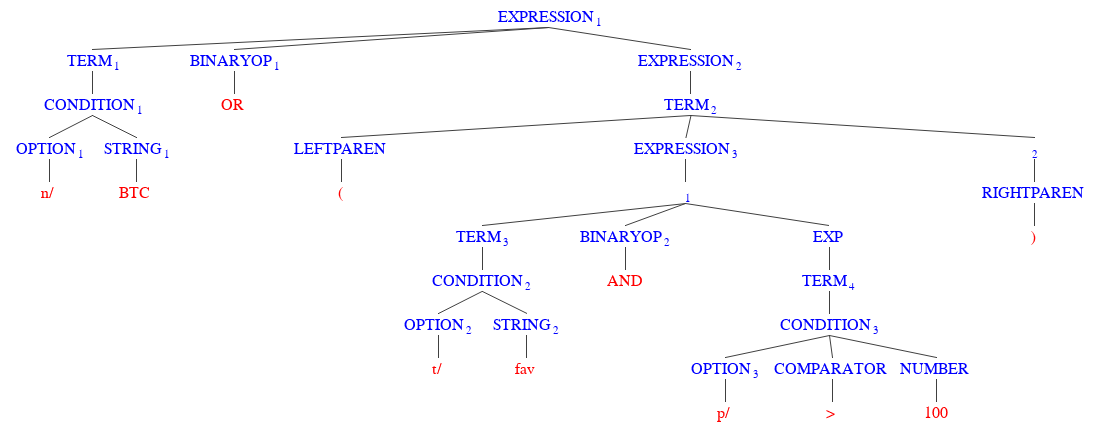
> [n/,OPTION][BTC,STRING][ OR ,BINARYOP][(,LEFTPAREN][t/,OPTION][fav,STRING][AND,BINRARYOP][p/,OPTION][>,COMPARATOR][100,NUMBER][),RIGHTPAREN]Using our example, we will illustrate how we can sequentially express the above tokenized argument based on the provided rules:
-
EXPRESSION -
TERMBINARYOPEXPRESSION -
CONDITIONBINARYOPEXPRESSION -
OPTIONSTRINGBINARYOPEXPRESSION -
n/STRINGBINARYOPEXPRESSION -
n/BTCBINARYOPEXPRESSION -
n/BTCOREXPRESSION -
n/BTCORTERM -
n/BTCOR(EXPRESSION) -
n/BTCOR(TERMBINARYOPEXPRESSION) -
n/BTCOR(CONDITIONBINARYOPEXPRESSION) -
n/BTCOR(OPTIONSTRINGBINARYOPEXPRESSION) -
n/BTCOR(t/STRINGBINARYOPEXPRESSION) -
n/BTCOR(t/favBINARYOPEXPRESSION) -
n/BTCOR(t/favANDEXPRESSION) -
n/BTCOR(t/favANDTERM) -
n/BTCOR(t/favANDCONDITION) -
n/BTCOR(t/favANDOPTIONCOMPARATORNUM) -
n/BTCOR(t/favANDp/COMPARATORNUM) -
n/BTCOR(t/favANDp/>NUM) -
n/BTCOR(t/favANDp/>100)
The recursive methods Expression, Term, Condition in the syntax parser class will match their own respective tokens
as necessary. In fact the method calls in the parser are exactly the same as the matches made in the previously stated sequence.
For example, here is the implementation for EXPRESSION.
boolean expression() {
if (!term()) {
return false;
}
while (tokenStack.matchAndPopTokenType(TokenType.BINARYBOOL)) {
if (!term()) {
return false;
}
}
return true;
}Visually we can represent sequence of matching with the following parse tree (Fig. 14), which also serves as the recursion tree:
Semantic Parser
Following up, the Semantic Parser has to verify that the conditions are correct. This can be done by verifying the type of the condition versus the parameters that follow. For example, a name condition should only be followed by a string. This can be done by checking the corresponding option class versus the type of token that follows.
Thus, the checks that are made are just to ensure every string type option is followed by a string and every number type option is followed by a number.
Condition Generator
Lastly, the condition generator creates lambdas based on the type of conditions found, and then recursively composes each condition based on the binary operators encounters up the recursion tree.
The final Condition object is actually just a composition of many individual Condition objects. This can be done
as a back call at the end of each recursion tree.
For example, consider the following argument:
p/>100 AND t/favp/>100 is a condition on price whereas t/fav is a condition on tags, and they can be composed using the Predicate
method and() to return a logical conjunction of the two conditions.
Design Considerations
Aspect: Specification of syntax
-
Alternative 1 (current choice): Have the structure of the methods reflect exactly the syntax.
-
Pros: Any subsequent changes can be easily made by having the code reflect the new syntax, since the syntax is apparent.
-
Cons: It is more cumbersome to have to alter the code every time there is a change in syntax.
-
-
Alternative 2: Specify the syntax in a separate file (e.g. EBNF file), and metaprogram the parser based on the file.
-
Pros: This requires no code change whenever the syntax has to be modified.
-
Cons: The code to support this would be more complicated and not apparent to developers immediately.
-
Aspect: Implementation of SyntaxParser, SemanticParser, ConditionGenerator
-
Alternative 1 (current choice): Have separate classes that have the same structure but with different return values.
-
Pros: This approach maintains SRP.
-
Cons: A change in syntax will require changes across 3 classes. It is also very redundant to have similar code.
-
-
Alternative 2: Have a single implementation that performs syntax parsing, semantic parsing and the condition generation.
-
Pros: There will be less redundant code.
-
Cons: This approach clearly violates SRP.
-